


Mit dem 14. Februar 2022 hatte das Wiener Museum Belvedere einen symbolträchtigen Tag für einen ungewöhnlichen Marktstart gewählt: Eine digitale Kopie von Gustav Klimts berühmten Gemälde „Der Kuss“ wurde in 10.000 Einzelteile aufgeteilt, die in Form durchnummerierter NFTs erworben werden konnten. Kostenpunkt der Liebeserklärung: 1850 Euro pro Stück. Während das dem Belvedere Einnahmen von 4,4 Millionen Euro brachte, haben jene Käufer, die die NFTs auch als Anlage sahen, weniger Glück. Das Kuss-Stückchen Nummer 07542 hat Mitte Mai um 0,11 ETH den Besitzer gewechselt – zu dem Zeitpunkt umgerechnet etwa 217 Euro. Das Interesse an den Klimt-NFTs ist bereits mit Anfang März eingebrochen und dazu kam nun noch ein Kursverfall von Ethereum.
Gute Gewinne im Februar
Kurz nach dem Sale durch das Belvedere gab es Tage auf der Handelsplattform OpenSea, an denen bis zu 18 Kuss-Deals abgewickelt wurden. Der durchschnittliche Handelspreis lag damals noch bei teilweise mehr als 1 ETH und der Ethereum-Kurs lag im Februar an den guten Kiss-Handelstagen bei über 3000 Dollar. Im Februar waren mit den frischen Klimt-NFTs also noch gute Gewinne einzufahren. Im März brach der durchschnittliche Preis bereits an vielen Tagen auf rund 0,4 und vereinzelt sogar auf rund 0,2 ETH ein. Und mittlerweile liegt der Verkaufswert in Einzelfällen eben bei umgerechnet nur noch über 200 Euro – ein Wertverlust von 87 Prozent, wie der oberösterreichische Kulturmanager Thomas Diesenreiter auf Twitter vorrechnet.
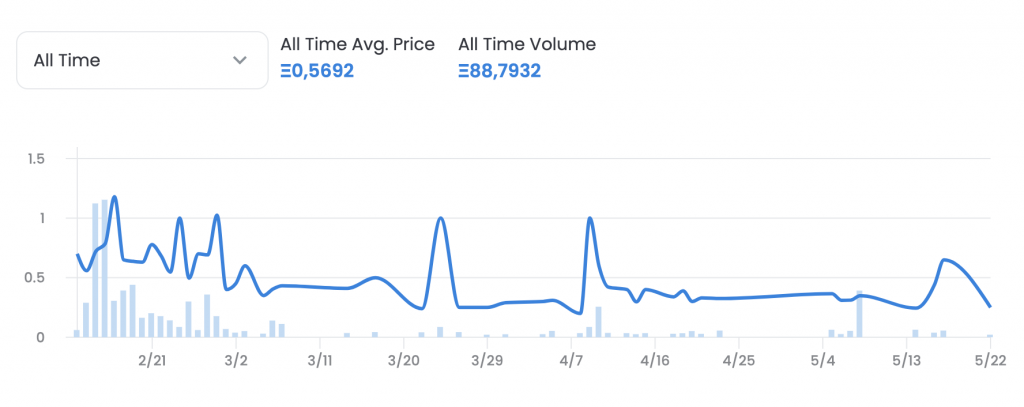
Kaum Interesse an berühmtem NFT
Der NFT-Wertverfall beschränkt sich nicht auf die Kuss-Teilchen, sondern spiegelt die derzeitige Marktlage wieder. Vor etwa einem Jahr wurde medienwirksam ein NFT des ersten Tweets von Twitter-Co-Founder Jack Dorsey verkauft – um damals umgerechnet 2,9 Millionen Dollar. Ein Jahr später wollte der Besitzer das NFT wieder verkaufen, erhielt aber lediglich Gebote von rund 7.000 Dollar und entschied sich gegen einen Verkauf. NFTs werden in der Regel in Ethereum gehandelt – der Preis der zweitwichtigsten Kryptowährung nach Bitcoin lag Anfang April noch bei teilweise mehr als 3500 Dollar und rutschte im Mai unter die Grenze von 2000 Dollar.
In diesem ungünstigen Umfeld wagt sich ein weiteres Wiener Traditionsmuseum an das neue Geschäftsfeld. Das Leopold Museum bietet seit Anfang Mai eine NFT-Kollektion von digitalen Versionen von insgesamt 24 Werken Egon Schieles an. Während das Belvedere mit dem Startup arteQ zusammenarbeitet, setzt das Leopold Museum auf die NFT-Plattform LaCollection und die Österreichische Post als Partner. Je nach Anzahl der NFTs pro Werk, sind die Schiele-Tokens noch bis 26. Mai zu Preisen von 499 Euro bis 100.000 Euro erhältlich.
Disclaimer: Dieser Text sowie die Hinweise und Informationen stellen keine Steuerberatung, Anlageberatung oder Empfehlung zum Kauf oder Verkauf von Wertpapieren dar. Sie dienen lediglich der persönlichen Information. Es wird keine Empfehlung für eine bestimmte Anlagestrategie abgegeben. Die Inhalte von brutkasten.com richten sich ausschließlich an natürliche Personen.






