


Die Kurstafel:
📈 Starke Woche am Markt
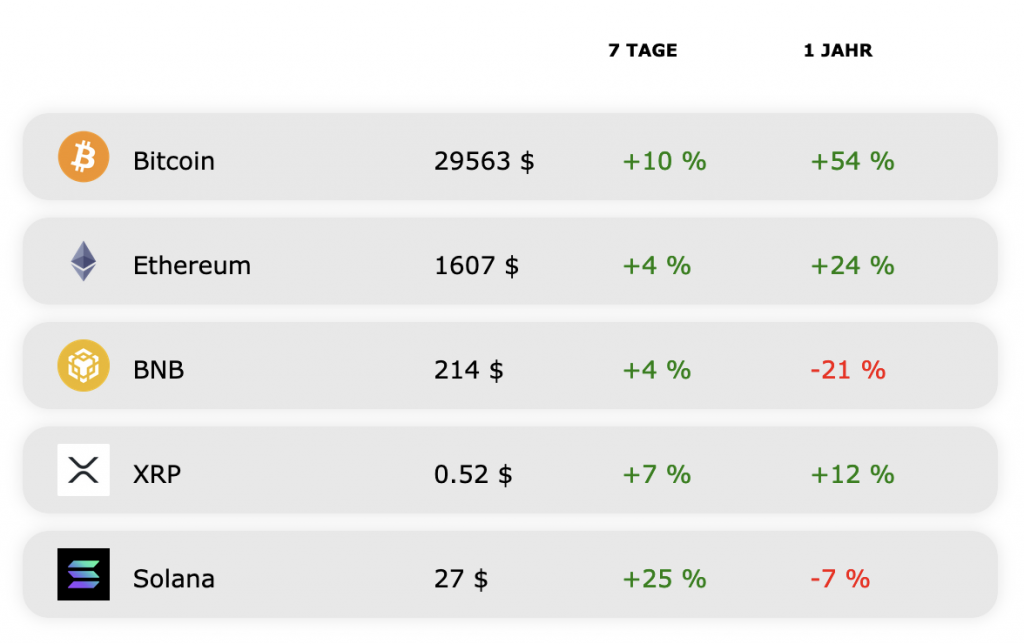
Es ging wieder aufwärts am Kryptomarkt in dieser Woche. Die Kurse aller großen Krypto-Assets liegen gegenüber vergangenem Freitag im Plus.
Interessant dabei: Die traditionellen Finanzmärkte standen diese Woche unter Druck. Der militärische Konflikt im Nahen Osten sorgt für Unsicherheit. Im Normalfall zieht so etwas auch die Kryptokurse mit nach unten: Weil Kryptowährungen am Markt als typische Risk Assets eingeordnet werden, von denen man sich in Phasen hoher Unsicherheit vorsichtshalber trennt.
Aber nicht so in dieser Woche. Da hielten sich die Krypto-Kurse trotz des schwachen Umfelds mehr als nur gut. Bitcoin stieg am Freitag zwischenzeitlich sogar über die 30.000-Dollar-Marke. Hintergrund ist ein Thema, das schon im Sommer einige Zeit die Kurse trieb: Bitcoin-ETFs in den USA.
Da dieses Thema in Crypto Weekly bereits dermaßen oft beleuchtet wurde, hier nur mehr die Kurzfassung zum Kontext: Noch nie ist in den USA ein ETF zugelassen worden, der direkt in Bitcoin investiert (statt in Finanzprodukte, die den Bitcoin-Preis nachbilden). Im Juni wurde bekannt, dass der weltgrößte Vermögensverwalter BlackRock einen Antrag auf einen solchen ETF bei der US-Börsenaufsicht eingereicht hat (siehe Crypto Weekly #104). Und BlackRock hat in den USA eine gute Bilanz bei ETF-Anträgen: 575 mal wurden diese genehmigt, nur einmal abgelehnt.
Ende August kam dann noch ein Gerichtsurteil dazu. In einem anderen Fall, in dem es aber ebenfalls um einen Bitcoin-ETF geht. Der Vermögensverwalter Grayscale wollte (und will weiterhin) seinen Bitcoin Trust in einen ETF umwandeln. Die Börsenaufsicht lehnte dies ab, Grayscale klagte. Ein Gericht entschied: Die Behörde hat nicht ausreichend begründet, warum der Antrag abgelehnt wurde (siehe Crypto Weekly #113).
😮 US-Börsenaufsicht beeinsprucht Grayscale-Urteil nicht
Danach wurde es um das Thema wieder ruhiger (siehe Crypto Weekly #116). Nun kam aber wieder Bewegung rein. Zunächst einmal gab es Neuigkeiten im Grayscale-Fall. Die US-Börsenaufsicht werde das Urteil nicht beeinspruchen, berichtete zunächst die Nachrichtenagentur Reuters am vergangenen Freitagabend. Und das bestätigte sich dann tatsächlich, die Behörde ließ eine entsprechende Frist verstreichen.
Dazu muss man anmerken: Daraus folgt nicht, dass die Börsenaufsicht den Antrag genehmigen muss. Sie hat lediglich das Urteil akzeptiert, dass sie ihre ursprüngliche Entscheidung nicht ausreichend begründet hat.
Das heißt auch: Sie könnte einen erneuten Antrag ebenfalls wieder ablehnen – nur eben mit einer anderen Begründung. Hier könnte man jedoch wieder argumentieren: Wenn sie bessere andere Begründungen haben, warum haben sie die dann nicht gleich angeführt? Wie dem aber auch sei, klar ist jedenfalls: Dass die Börsenaufsicht das Urteil nicht beeinsprucht, ist für Grayscale jedenfalls besser als umgekehrt.
🙈 Wie eine Falschmeldung Bitcoin nach oben springen ließ
Am Montag folgte dann schon die nächste große Nachricht zum Thema. Diesmal aber nicht zum Grayscale-Antrag, sondern zu jenem von BlackRock. Die Börsenaufsicht habe diesen nun genehmigt, berichtete die Krypto-Newsseite Cointelegraph. Der Kurs von Bitcoin reagierte sofort und zog deutlich an.
Die Sache hatte aber einen Haken: Es war eine völlige Falschmeldung. BlackRock selbst dementierte die vermeintliche Neuigkeit auch rasch. Der Antrag werde weiterhin von der Börsenaufsicht geprüft, sagte ein Sprecher des Vermögensverwalters.
Nachdem dies klar geworden war, fiel der Bitcoin-Kurs zunächst wieder etwas zurück. In den folgenden Tagen ging es jedoch weiter aufwärts – nicht wegen der Falschmeldung, aber ein Zusammenhang zur größeren Thematik Bitcoin-ETFs kann durchaus angenommen werden. Der Optimismus in der Kryptobranche zu dem Thema nahm zuletzt wieder zu.
Sowohl BlackRock als auch Fidelity – ein weiterer Vermögensverwalter, der einen Antrag auf einen Bitcoin-ETF eingebracht hatte – nahmen diese Woche an ihren Anträgen Ergänzungen vor. Am Markt wurde dies als positiv interpretiert.
Unterstützend wirkte diese Woche außerdem ein Report von JPMorgan. Die Analysten der US-Großbank gehen darin davon aus, dass Bitcoin-ETFs in den nächsten Monaten genehmigt werden dürften – “höchstwahrscheinlich vor dem 10. Jänner 2024”, wie es in dem Report heißt. Dabei handelt es sich um die letzte Frist für die ebenfalls bei der Börsenaufsicht liegenden Anträge von Ark Invest und 21Shares, die zuletzt verlängert worden war (siehe Crypto Weekly #116)
Entscheidend sind diese Dinge natürlich allesamt nicht. Aber sie sind positive Indizien, was die Genehmigung von Bitcoin-ETFs angeht – oder werden zumindest am Markt als solche interpretiert. Ob sich die Markteinschätzung als richtig erweisen wird, werden die nächsten Monate zeigen.



