NÖ-EduTech-Startup QuickSpeech: “User nimmt es nicht als Lernen wahr”
Das niederösterreichische Startup QuickSpeech will mit seiner Software-Lösung und App das Lernen im Unternehmen zukunftsfit machen. Ein Covid-19-Kurs wird vom Accent-Teilnehmer derzeit kostenlos zu Verfügung gestellt.
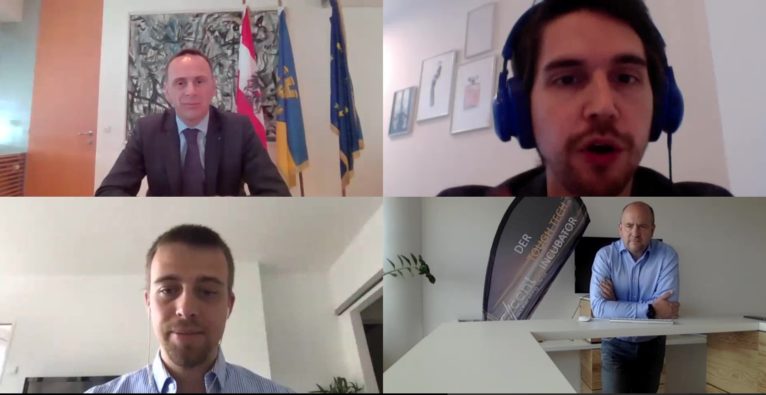
(c) accent: Wirtschaftslandesrat Jochen Danninger, Company Builder Kambis Kohansal Vajargah, QuickSpeech-Gründer Lukas Snizek und accent-Geschäftsführer Michael Moll bei der virtuellen Betriebsbesichtigung
“Lebenslanges Lernen” ist für die meisten Unternehmen längst keine hohle Phrase mehr. Denn nicht nur beim Onboarding und bei der Lehrlings- bzw. Trainee-Ausbildung müssen sie Mitarbeitern Wissen vermitteln. Man denke nur an Fortbildungen, Trainings für neue Produkte und Systeme oder betriebliche Qualitätssicherungsmaßnahmen. Doch wie bringt man das Wissen, das für die korrekte Ausübung des Berufs und damit ein gut funktionierendes Unternehmen notwendig ist, an die Mitarbeiter? Und das auf eine für alle Seiten angenehme Arte und Weise? Mit diesen Fragen hat sich Lukas Snizek, Gründer des niederösterreichischen EduTech-Startups QuickSpeech beschäftigt – und entwickelte einen eigenen Gamification-Ansatz.
Die Software-Lösung des Startups mit dazugehöriger App ermöglicht es Unternehmen, ihren Mitarbeitern Inhalte auf spielerische Weise zu vermitteln. Mit Erklärungen bzw. Erklärvideos und anschließenden Single oder Multiple Choice-Quizzes wird das Wissen in “kleinen Häppchen” von zwei bis drei Minuten pro Tag weitergegeben. Die Mitarbeiter können Punkte sammeln und sich damit vom Unternehmen ausgewählte Goodies oder Incentives wie Gutscheine oder sogar zusätzliche freie Tage holen. “Der User selbst nimmt es nicht wirklich als Lernen wahr”, sagt Gründer Snizek bei einer “virtuellen Betriebsbesichtigung” mit dem niederösterreichischen Wirtschaftslandesrat Jochen Danninger.
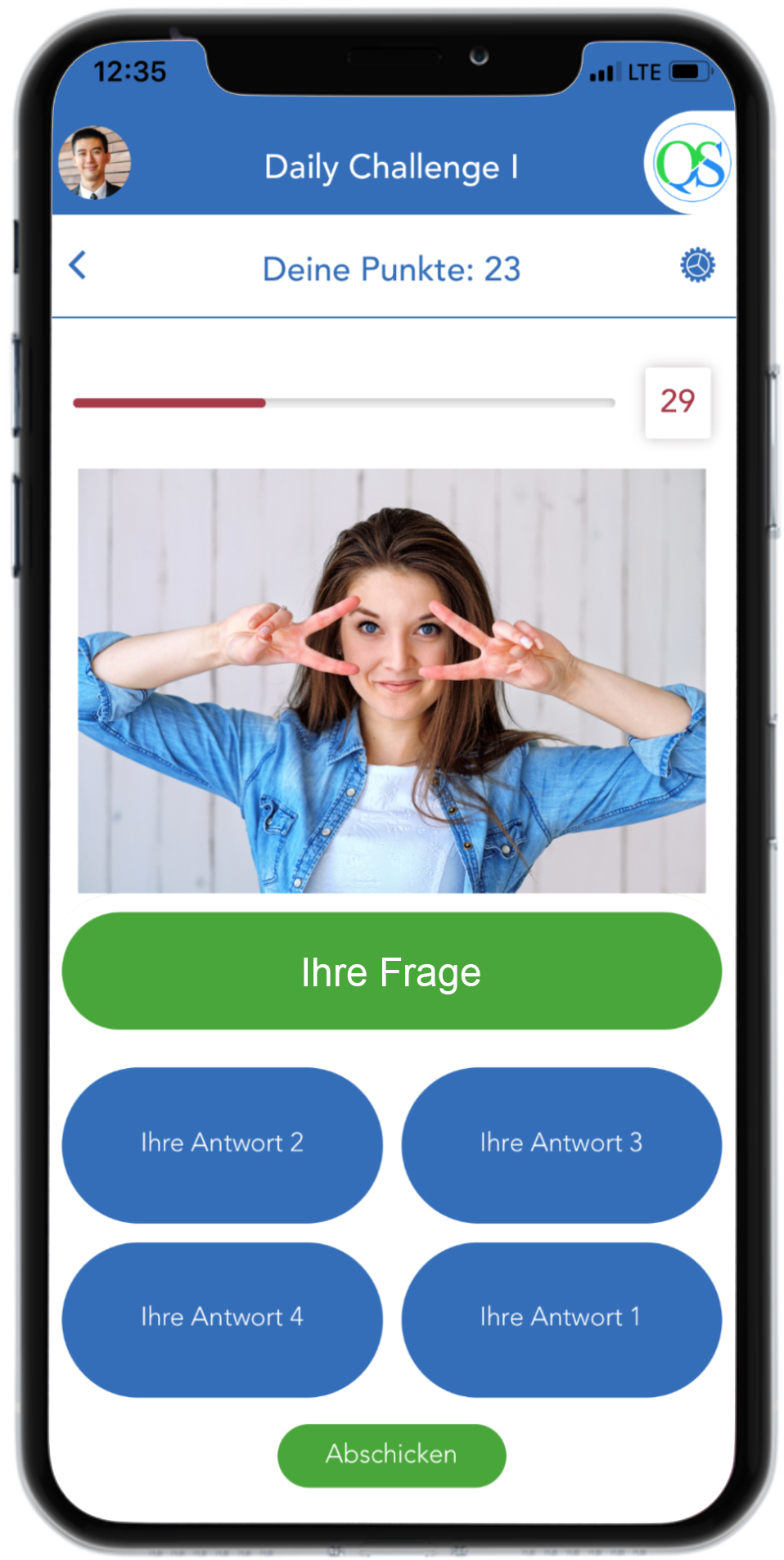
So sieht die QuickSpeech-Oberfläche aus
15 B2B-Kunden aus unterschiedlichsten Branchen
Die Zahlen, die Snizek nennt, sprechen für sich. Bei etwa 4000 App-Usern habe man eine Rate von 75 Prozent täglich wiederkehrender Nutzer. In der jüngsten Altersgruppe – hier geht es vor allem um Lehrlinge – liege die Rate bei 94 Prozent. Für die Unternehmenskunden – derzeit zählt QuickSpeech 15 aus Industrie und Branchen wie Energiewirtschaft, Einzelhandel und Banking – gibt es dabei unterschiedliche Möglichkeiten. Sie können für ihre Mitarbeiter entweder einzelne Premium-Kurse zu Themen wie Compliance, Verkaufstrainings, Microsoft Office, Projektmanagement, DSGVO und Cyber Security oder eine Lizenz kaufen.
Maßgeschneiderte Kurse möglich
In der zweiten Option sind maßgeschneiderte Kurse, die in Kooperation mit Bildungseinrichtungen innerhalb von nur einer Woche erstellt werden, möglich. Auch können die Administratoren der Unternehmen dann über ein Dashbord selbst Inhalte managen und etwa Statistiken einsehen. “Die meisten Kunden nutzen beides”, erklärt Snizek. Für die geplante Expansion – zunächst im DACH-Raum und dann in weitere europäische Länder, will man das Onboarding der Kunden noch weiter vereinfachen und beschleunigen.
Kostenloser Covid-19-Premium-Kurs soll auch Neukunden bringen
Nun in der Coronakrise erlebe man eine verstärkte Nachfrage nach diesem digitalen Kommunikationsweg mit den Mitarbeitern. “Uns wird nicht langweilig”, so der Gründer. Zudem bietet QuickSpeech einen eigenen Premium-Kurs zum Thema Covid-19-Hygiene-Maßnahmen – und zwar derzeit kostenlos. “Unternehmen aus dem Tourismusbereich können ihre Mitarbeiter damit z.B. jetzt auf den neuen Modus nach der Wiedereröffnung einschulen. Später, wenn diese Unternehmen wieder Umsätze haben, wollen wir das in einen ‘pay as you like’-Modus überführen und sie werden hoffentlich dauerhaft zu Kunden”, erklärt Snizek. Zudem habe man den Covid-19-Kurs bereits bei zehn Bestandskunden ausgerollt.
Accent ebnete QuickSpeech den Weg
Entstanden ist QuickSpeech 2018 an der FH St. Pölten. Aus dem Creative Pre-Incubator (CPI) von Accent ging das Startup in den Tough Tech Incubator über. “Accent war von Beginn an sehr wichtiger Partner. Der CPI ist eine wirklich coole Sache, wo schon in Ideenphase gemeinsam an der Idee gefeilt wird. Es war ein Privileg, nachher in das Accent-Förderprogramm aufgenommen zu werden. Die Coachings, etwa zu Investorenansprache oder Steuer-Themen haben uns schon bislang sehr weitergebracht”, meint Snizek. Zuletzt nahm das Startup auch an einem Kooperationsprogramm von Accent mit Programmen anderer europäischer Regionen teil, das die Expansion in die jeweiligen Länder erleichtern soll.
Open Source und KI: “Es geht nicht darum, zu den Guten zu gehören”
Nachlese. Die Nutzung von Open-Source-Modellen eröffnet Unternehmen auch im KI-Bereich weitreichende Möglichkeiten. Es gibt dabei aber auch einiges zu bedenken. Darüber und mehr diskutierten in Folge 5 von "No Hype KI" Stephan Kraft von Red Hat, Florian Böttcher von CANCOM Austria, Natalie Ségur-Cabanac von Women in AI und Patrick Ratheiser von Leftshift.One.
Open Source und KI: “Es geht nicht darum, zu den Guten zu gehören”
Nachlese. Die Nutzung von Open-Source-Modellen eröffnet Unternehmen auch im KI-Bereich weitreichende Möglichkeiten. Es gibt dabei aber auch einiges zu bedenken. Darüber und mehr diskutierten in Folge 5 von "No Hype KI" Stephan Kraft von Red Hat, Florian Böttcher von CANCOM Austria, Natalie Ségur-Cabanac von Women in AI und Patrick Ratheiser von Leftshift.One.
Kollaborativ, transparent, frei zugänglich und nicht profit-orientiert – mit Open-Source-Software wird eine Reihe von Eigenschaften assoziiert. Und oftmals stehen bei der Nutzung ethische Überlegungen im Zentrum. Dabei gibt es auch ganz praktische Gründe, die für eine Verwendung durch Unternehmen sprechen – auch bei der Implementierung von KI-Anwendungen, ist Stephan Kraft, Community Advocate & Business Development OpenShift & Application Services bei Red Hat, überzeugt. In Folge fünf der Serie “No Hype KI” diskutierte er dieses und weitere Themen mit Florian Böttcher, Solution Architect bei CANCOM Austria, Natalie Ségur-Cabanac, Policy Lead bei Women in AI und Patrick Ratheiser, Gründer & CEO von Leftshift.One.
“Thema ein Stück weit aus dieser emotionalen, moralisierenden Ecke herausholen”
“Ich will das Thema ein Stück weit aus dieser emotionalen, moralisierenden Ecke herausholen”, sagt Stephan Kraft. Für Red Hat als weltweit führenden Anbieter für Open-Source-Lösungen für Unternehmen gehen die Argumente für eine Nutzung nämlich weit darüber hinaus. “Es geht nicht darum, Open Source als Selbstzweck zu sehen, um zu den Guten zu gehören”, so der Experte. Tatsächlich sei die Verwendung von Open Source gerade bei der Etablierung von KI im Unternehmen für Startups und KMU eine wichtige Weichenstellung.
Offenheit, um Diskriminierung entgegenzuwirken
Auch Natalie Ségur-Cabanac sieht Open Source als “Key Technology” im KI-Bereich. Für “Women in AI” spiele die Offenheit eine zentrale Rolle: “Diese Offenheit braucht es, um Diskriminierung entgegenzuwirken.” Open Source verbessere den Zugang für Frauen zur Technologie, die Abbildung von Frauen in den Daten und es vergrößere die Möglichkeiten in der Forschung. Man müsse aber auch aufpassen, ob Software wirklich so offen sei, wie behauptet, sagt sie bezogen auf die aktuellen Diskussionen rund um OpenAI, das sich – ursprünglich als offenes Projekt gestartet – zum profitorientierten Unternehmen entwickelte. Es brauche auch eine klare Definition, was “open” sei.
Masse an Möglichkeiten
Leftshift.One-Gründer Patrick Ratheiser betont auch die schiere Masse an Möglichkeiten, die Open Source bietet. “2021 hatten wir weltweit Zugriff auf circa 5.000 Open-Source-Modelle. Jetzt sind es bereits mehr als eine Million.” Die Nutzbarkeit sei also klar gegeben, zudem biete die Technologie eine gewisse Unabhängigkeit und werde über ihre Vielfalt zum Innovationstreiber.
Ist Open Source immer die beste Lösung?
Doch bedeutet das, dass Open Source immer die optimale Lösung ist? Ratheiser sieht das differenziert: “Es ist ganz wichtig zu erkennen, was der Kunde braucht und was in dem Fall gerade notwendig ist. Egal, ob es nun On-Premise, in der Cloud, Open Source oder Closed Source ist.” Florian Böttcher von CANCOM Austria pflichtet hier bei: “Wir setzen genau so auf hybrid.”
Datenstruktur im Hintergrund ist entscheidend
Ein Thema, bei dem bei Open Source Vorsicht geboten ist, spricht Natalie Ségur-Cabanac an. Besonders wichtig sei es bei KI-Anwendungen, eine gute Datenstruktur im Hintergrund zu haben. “Die Verantwortung, dass ein Modell mit sauberen Daten trainiert worden ist, liegt bei den Anbietern. Bei Open Source verschwimmt das ein bisschen. Wer ist wofür zuständig? Das ist eine Herausforderung für die Compliance zu schauen, wo man selbst verantwortlich ist und wo man sich auf einen Anbieter verlassen kann.”
Compliance: Großes Thema – mehr Sichereheit mit professioneller Unterstützung
Stephan Kraft hakt hier ein. Genau aus solchen Gründen gebe es Unternehmen wie Red Hat, die mit ihrem Enterprise-Support für Open-Source-Lösungen die Qualitätssicherung auch im rechtlichen Bereich übernehmen. “Das ist ein ganz wichtiger Teil unseres Versprechens gegenüber Kunden”, so Kraft. Unbedacht im Unternehmen mit Open Source zu arbeiten, könne dagegen in “Compliance-Fallen” führen, pflichtet er Ségur-Cabanac bei.
Das sieht auch Patrick Ratheiser als Thema bei Leftshift.One: “Unsere Lösung ist Closed Source, wir setzen aber im Hintergrund Open Source ein. Wichtig ist, dass wir dem Kunden Compliance garantieren können.” Stephan Kraft empfiehlt Unternehmen bei der Open-Source-Nutzung: “Man kann nicht immer gleich die neueste ‘bleeding edge’-Lösung nehmen sondern sollte etwas konservativer herangehen.”
Infrastruktur: Gut planen, was man wirklich braucht
Unabhängig davon, ob man nun Open Source oder Closed Source nutzt, braucht es für die Nutzung von KI die richtige Infrastruktur. “Es kommt natürlich auf den Use Case an, den ein Unternehmen umsetzen will. Da sind die Anforderungen an die Infrastruktur sehr unterschiedlich”, grenzt Florian Böttcher ein. CANCOM Austria unterstützt seine Kunden in genau der Frage. Anwendungen wie das Training von KI-Modellen würde aus gutem Grund kaum in Österreich umgesetzt. “KI ist sehr stromhungrig und entwickelt viel Hitze. Das ist schwierig für ein eigenes Data-Center im Unternehmen, gerade wenn man die Strompreise in Österreich ansieht”, so Böttcher.
“Rechenleistungs-Hunger” von KI könnte sich in Zukunft verringern
Wichtig sei es letztlich, sich als Unternehmen sehr klar darüber zu sein, was man umsetzen wolle. “Danach, welche Software-Lösung man für seinen Use Case einsetzen muss, richtet sich auch die Infrastruktur”, so Böttcher. Er erwarte aber auch, dass die KI-Modelle im nächsten Entwicklungsschritt effizienter werden und der “Rechenleistungs-Hunger” sich verringere.
Patrick Ratheiser ergänzt: “Es ist grundsätzlich eine Kostenfrage.” Unternehmen müssten sich sehr gut überlegen, ob sie ein eigenes LLM (Large Language Model) betreiben und dieses sogar selbst trainieren wollen, oder lieber doch eine Usage-basierte Lösung wählen. Er sehe bei österreichischen Unternehmen – auch bei größeren – eine klare Tendenz zur zweiten Variante. “Es lässt sich deutlich schneller einrichten, ist kalkulierbarer und auch viel schneller skalierbar”, erklärt Ratheiser.
Etwa im Forschungsbereich sei es jedoch wichtig und notwendig, auch eigene LLMs und die damit verbundene Infrastruktur zu betreiben. Doch auch die Möglichkeit von hybriden Lösungen biete sich an. “Man kann mittlerweile auch Teile in der Cloud lassen und Teile On-Premise. Man kann etwa nur ein datenschutzsicheres LLM selbst betreiben”, erklärt der Experte, der auch bei der Wahl der genutzten Modelle einen hybriden Ansatz empfiehlt: “Man braucht nicht für alle Use Cases das neueste Modell. Manchmal braucht man überhaupt kein LLM.”
Datenschutz: Einige Herausforderungen bei LLMs
Stichwort: Datenschutz. Hier schafft die europäische Datenschutzgrundverordnung (DSGVO) im KI-Bereich besondere Herausforderungen, weiß Natalie Ségur-Cabanac, die vorab betont: “Ich persönlich halte die DSGVO für ein gutes Regulierungswerk, weil sie sehr viel Spielraum gibt. Ich sage immer: Datenschutz ist sehr komplex, aber nicht kompliziert.” Konkret seien etwa der Grundsatz der Zweckbezogenheit, also dass man Daten nur für konkrete Zwecke einsetzen darf, und dass man sie minimierend einsetzen muss, relevant für den KI-Bereich. “Da haben wir schon einen Konflikt, weil man ja [bei LLMs] erst einmal schaut, was man aus möglichst vielen Daten machen kann”, so die Expertin.
Ist KI rechtlich innerhalb der EU sogar per se in einem Graubereich?
Auch Transparenzbestimmungen – sowohl in der DSGVO als auch im AI-Act der EU – seien zu beachten. “Wenn ich KI verwende, muss ich auch wissen, was drinnen ist”, fasst Ségur-Cabanac zusammen. Ist KI also rechtlich innerhalb der EU sogar per se in einem Graubereich? “Nein, das glaube ich nicht. Aber man muss seine Hausaufgaben schon gut machen”, sagt die Expertin. Wichtig sei daher auch die im Rahmen des EU-AI-Acts eingeforderte KI-Kompetenz in Unternehmen – im technischen und rechtlichen Bereich.
KI-Kompetenz als zentrales Thema
Patrick Ratheiser stimmt zu: “Neben der Technologie selber sind bei unseren Kunden die Mitarbeiter ein Riesen-Thema. Man muss sie nicht nur wegen dem AI-Act fit bekommen, sondern es geht darum, sie wirklich auf die Anwendungen einzuschulen.” Wichtig seien dabei auch die Kolleg:innen, die sich bereits mit dem Thema auskennen – die “Pioniere” im Unternehmen. “AI Literacy ist sicherlich das Thema 2025 und in nächster Zeit. So, wie wir gelernt haben, mit dem Smartphone umzugehen, werden wir es auch mit generativer KI lernen”, so Ratheiser.
“Einfach einmal ausprobieren”
Stephan Kraft ergänzt: Neben einer soliden Datenbasis und der notwendigen Kompetenz brauche es bei KI – gerade auch im Bereich Open Source – noch etwas: “Einfach einmal ausprobieren. Es braucht auch Trial and Error. Das ist vielleicht oft das Schwierigste für CFOs und Geschäftsführer.” Dieses Ausprobieren sollte aber innerhalb eines festgelegten Rahmens passieren, damit die KI-Implementierung gelingt, meint Natalie Ségur-Cabanac: “Unternehmen brauchen eine KI-Strategie und müssen wissen, was sie mit der Technologie erreichen wollen.” Auch sich mit den zuvor angesprochenen rechtlichen Anforderungen – Stichwort Compliance – zu beschäftigen, komme zeitlich erst nach der Festlegung der Strategie.
Open Source und KI: “Es geht nicht darum, zu den Guten zu gehören”
Nachlese. Die Nutzung von Open-Source-Modellen eröffnet Unternehmen auch im KI-Bereich weitreichende Möglichkeiten. Es gibt dabei aber auch einiges zu bedenken. Darüber und mehr diskutierten in Folge 5 von "No Hype KI" Stephan Kraft von Red Hat, Florian Böttcher von CANCOM Austria, Natalie Ségur-Cabanac von Women in AI und Patrick Ratheiser von Leftshift.One.
Open Source und KI: “Es geht nicht darum, zu den Guten zu gehören”
Nachlese. Die Nutzung von Open-Source-Modellen eröffnet Unternehmen auch im KI-Bereich weitreichende Möglichkeiten. Es gibt dabei aber auch einiges zu bedenken. Darüber und mehr diskutierten in Folge 5 von "No Hype KI" Stephan Kraft von Red Hat, Florian Böttcher von CANCOM Austria, Natalie Ségur-Cabanac von Women in AI und Patrick Ratheiser von Leftshift.One.
Kollaborativ, transparent, frei zugänglich und nicht profit-orientiert – mit Open-Source-Software wird eine Reihe von Eigenschaften assoziiert. Und oftmals stehen bei der Nutzung ethische Überlegungen im Zentrum. Dabei gibt es auch ganz praktische Gründe, die für eine Verwendung durch Unternehmen sprechen – auch bei der Implementierung von KI-Anwendungen, ist Stephan Kraft, Community Advocate & Business Development OpenShift & Application Services bei Red Hat, überzeugt. In Folge fünf der Serie “No Hype KI” diskutierte er dieses und weitere Themen mit Florian Böttcher, Solution Architect bei CANCOM Austria, Natalie Ségur-Cabanac, Policy Lead bei Women in AI und Patrick Ratheiser, Gründer & CEO von Leftshift.One.
“Thema ein Stück weit aus dieser emotionalen, moralisierenden Ecke herausholen”
“Ich will das Thema ein Stück weit aus dieser emotionalen, moralisierenden Ecke herausholen”, sagt Stephan Kraft. Für Red Hat als weltweit führenden Anbieter für Open-Source-Lösungen für Unternehmen gehen die Argumente für eine Nutzung nämlich weit darüber hinaus. “Es geht nicht darum, Open Source als Selbstzweck zu sehen, um zu den Guten zu gehören”, so der Experte. Tatsächlich sei die Verwendung von Open Source gerade bei der Etablierung von KI im Unternehmen für Startups und KMU eine wichtige Weichenstellung.
Offenheit, um Diskriminierung entgegenzuwirken
Auch Natalie Ségur-Cabanac sieht Open Source als “Key Technology” im KI-Bereich. Für “Women in AI” spiele die Offenheit eine zentrale Rolle: “Diese Offenheit braucht es, um Diskriminierung entgegenzuwirken.” Open Source verbessere den Zugang für Frauen zur Technologie, die Abbildung von Frauen in den Daten und es vergrößere die Möglichkeiten in der Forschung. Man müsse aber auch aufpassen, ob Software wirklich so offen sei, wie behauptet, sagt sie bezogen auf die aktuellen Diskussionen rund um OpenAI, das sich – ursprünglich als offenes Projekt gestartet – zum profitorientierten Unternehmen entwickelte. Es brauche auch eine klare Definition, was “open” sei.
Masse an Möglichkeiten
Leftshift.One-Gründer Patrick Ratheiser betont auch die schiere Masse an Möglichkeiten, die Open Source bietet. “2021 hatten wir weltweit Zugriff auf circa 5.000 Open-Source-Modelle. Jetzt sind es bereits mehr als eine Million.” Die Nutzbarkeit sei also klar gegeben, zudem biete die Technologie eine gewisse Unabhängigkeit und werde über ihre Vielfalt zum Innovationstreiber.
Ist Open Source immer die beste Lösung?
Doch bedeutet das, dass Open Source immer die optimale Lösung ist? Ratheiser sieht das differenziert: “Es ist ganz wichtig zu erkennen, was der Kunde braucht und was in dem Fall gerade notwendig ist. Egal, ob es nun On-Premise, in der Cloud, Open Source oder Closed Source ist.” Florian Böttcher von CANCOM Austria pflichtet hier bei: “Wir setzen genau so auf hybrid.”
Datenstruktur im Hintergrund ist entscheidend
Ein Thema, bei dem bei Open Source Vorsicht geboten ist, spricht Natalie Ségur-Cabanac an. Besonders wichtig sei es bei KI-Anwendungen, eine gute Datenstruktur im Hintergrund zu haben. “Die Verantwortung, dass ein Modell mit sauberen Daten trainiert worden ist, liegt bei den Anbietern. Bei Open Source verschwimmt das ein bisschen. Wer ist wofür zuständig? Das ist eine Herausforderung für die Compliance zu schauen, wo man selbst verantwortlich ist und wo man sich auf einen Anbieter verlassen kann.”
Compliance: Großes Thema – mehr Sichereheit mit professioneller Unterstützung
Stephan Kraft hakt hier ein. Genau aus solchen Gründen gebe es Unternehmen wie Red Hat, die mit ihrem Enterprise-Support für Open-Source-Lösungen die Qualitätssicherung auch im rechtlichen Bereich übernehmen. “Das ist ein ganz wichtiger Teil unseres Versprechens gegenüber Kunden”, so Kraft. Unbedacht im Unternehmen mit Open Source zu arbeiten, könne dagegen in “Compliance-Fallen” führen, pflichtet er Ségur-Cabanac bei.
Das sieht auch Patrick Ratheiser als Thema bei Leftshift.One: “Unsere Lösung ist Closed Source, wir setzen aber im Hintergrund Open Source ein. Wichtig ist, dass wir dem Kunden Compliance garantieren können.” Stephan Kraft empfiehlt Unternehmen bei der Open-Source-Nutzung: “Man kann nicht immer gleich die neueste ‘bleeding edge’-Lösung nehmen sondern sollte etwas konservativer herangehen.”
Infrastruktur: Gut planen, was man wirklich braucht
Unabhängig davon, ob man nun Open Source oder Closed Source nutzt, braucht es für die Nutzung von KI die richtige Infrastruktur. “Es kommt natürlich auf den Use Case an, den ein Unternehmen umsetzen will. Da sind die Anforderungen an die Infrastruktur sehr unterschiedlich”, grenzt Florian Böttcher ein. CANCOM Austria unterstützt seine Kunden in genau der Frage. Anwendungen wie das Training von KI-Modellen würde aus gutem Grund kaum in Österreich umgesetzt. “KI ist sehr stromhungrig und entwickelt viel Hitze. Das ist schwierig für ein eigenes Data-Center im Unternehmen, gerade wenn man die Strompreise in Österreich ansieht”, so Böttcher.
“Rechenleistungs-Hunger” von KI könnte sich in Zukunft verringern
Wichtig sei es letztlich, sich als Unternehmen sehr klar darüber zu sein, was man umsetzen wolle. “Danach, welche Software-Lösung man für seinen Use Case einsetzen muss, richtet sich auch die Infrastruktur”, so Böttcher. Er erwarte aber auch, dass die KI-Modelle im nächsten Entwicklungsschritt effizienter werden und der “Rechenleistungs-Hunger” sich verringere.
Patrick Ratheiser ergänzt: “Es ist grundsätzlich eine Kostenfrage.” Unternehmen müssten sich sehr gut überlegen, ob sie ein eigenes LLM (Large Language Model) betreiben und dieses sogar selbst trainieren wollen, oder lieber doch eine Usage-basierte Lösung wählen. Er sehe bei österreichischen Unternehmen – auch bei größeren – eine klare Tendenz zur zweiten Variante. “Es lässt sich deutlich schneller einrichten, ist kalkulierbarer und auch viel schneller skalierbar”, erklärt Ratheiser.
Etwa im Forschungsbereich sei es jedoch wichtig und notwendig, auch eigene LLMs und die damit verbundene Infrastruktur zu betreiben. Doch auch die Möglichkeit von hybriden Lösungen biete sich an. “Man kann mittlerweile auch Teile in der Cloud lassen und Teile On-Premise. Man kann etwa nur ein datenschutzsicheres LLM selbst betreiben”, erklärt der Experte, der auch bei der Wahl der genutzten Modelle einen hybriden Ansatz empfiehlt: “Man braucht nicht für alle Use Cases das neueste Modell. Manchmal braucht man überhaupt kein LLM.”
Datenschutz: Einige Herausforderungen bei LLMs
Stichwort: Datenschutz. Hier schafft die europäische Datenschutzgrundverordnung (DSGVO) im KI-Bereich besondere Herausforderungen, weiß Natalie Ségur-Cabanac, die vorab betont: “Ich persönlich halte die DSGVO für ein gutes Regulierungswerk, weil sie sehr viel Spielraum gibt. Ich sage immer: Datenschutz ist sehr komplex, aber nicht kompliziert.” Konkret seien etwa der Grundsatz der Zweckbezogenheit, also dass man Daten nur für konkrete Zwecke einsetzen darf, und dass man sie minimierend einsetzen muss, relevant für den KI-Bereich. “Da haben wir schon einen Konflikt, weil man ja [bei LLMs] erst einmal schaut, was man aus möglichst vielen Daten machen kann”, so die Expertin.
Ist KI rechtlich innerhalb der EU sogar per se in einem Graubereich?
Auch Transparenzbestimmungen – sowohl in der DSGVO als auch im AI-Act der EU – seien zu beachten. “Wenn ich KI verwende, muss ich auch wissen, was drinnen ist”, fasst Ségur-Cabanac zusammen. Ist KI also rechtlich innerhalb der EU sogar per se in einem Graubereich? “Nein, das glaube ich nicht. Aber man muss seine Hausaufgaben schon gut machen”, sagt die Expertin. Wichtig sei daher auch die im Rahmen des EU-AI-Acts eingeforderte KI-Kompetenz in Unternehmen – im technischen und rechtlichen Bereich.
KI-Kompetenz als zentrales Thema
Patrick Ratheiser stimmt zu: “Neben der Technologie selber sind bei unseren Kunden die Mitarbeiter ein Riesen-Thema. Man muss sie nicht nur wegen dem AI-Act fit bekommen, sondern es geht darum, sie wirklich auf die Anwendungen einzuschulen.” Wichtig seien dabei auch die Kolleg:innen, die sich bereits mit dem Thema auskennen – die “Pioniere” im Unternehmen. “AI Literacy ist sicherlich das Thema 2025 und in nächster Zeit. So, wie wir gelernt haben, mit dem Smartphone umzugehen, werden wir es auch mit generativer KI lernen”, so Ratheiser.
“Einfach einmal ausprobieren”
Stephan Kraft ergänzt: Neben einer soliden Datenbasis und der notwendigen Kompetenz brauche es bei KI – gerade auch im Bereich Open Source – noch etwas: “Einfach einmal ausprobieren. Es braucht auch Trial and Error. Das ist vielleicht oft das Schwierigste für CFOs und Geschäftsführer.” Dieses Ausprobieren sollte aber innerhalb eines festgelegten Rahmens passieren, damit die KI-Implementierung gelingt, meint Natalie Ségur-Cabanac: “Unternehmen brauchen eine KI-Strategie und müssen wissen, was sie mit der Technologie erreichen wollen.” Auch sich mit den zuvor angesprochenen rechtlichen Anforderungen – Stichwort Compliance – zu beschäftigen, komme zeitlich erst nach der Festlegung der Strategie.
Aktuelle Nachrichten zu Startups, den neuesten Innovationen und politischen Entscheidungen zur Digitalisierung direkt in dein Postfach. Wähle aus unserer breiten Palette an Newslettern den passenden für dich.
We collect and process your data on this site to better understand how it is used. You can give your consent to all or selected purposes, or you can decline them all. For more information, see our privacy policy.
AnalyticsWe'll collect information about your visit to our site. It helps us understand how the site is used – what's working, what might be broken and what we should improve.
RemarketingWe'll use your data to show you more relevant ads on other sites and social media. We'll use it to measure how effective our ads are. We'll also use it to exclude you from campaigns that you might not like.
User feedbackWe'll use your data to learn how our user interface is working. It'll help us to improve our site for all users.