


Wer anderen eine Grube gräbt, fällt selbst hinein. Das gilt auch für Milliardäre wie Mark Cuban. In den USA ist Cuban ein household name, man kennt ihn. Er ist oft im Fernsehen, besitzt ein NBA-Team – die Dallas Mavericks. Sein Vermögen beläuft sich laut Forbes auf mehr als vier Milliarden Dollar. Aber gestern hat es sich ein bisschen verringert.
Cuban gilt als großer Fan von „decentralized finance“, DeFi. Das ist ein etwas schwammiger Überbegriff für verschiedene Protokolle und Plattformen, die Finanzgeschäfte ermöglichen. Dazu gehören dezentrale Börsen, die für die Bereitstellung von Liquidität einen Teil der Handelsgebühren auszahlen.
Es gibt Kreditplattformen, die man als Gläubiger und als Schuldner nutzen kann. Und verschiedene Stablecoin-Projekte, also Coins, die meist den Wert des US-Dollar widerspiegeln und als Basis für die anderen Geschäfte dienen. Man muss sich das vorstellen wie ein Finanzsystem auf der Blockchain, auf Ethereum, Polkadot, Solana, Tezos und so weiter. Ohne Regulierung. Ohne Netz. Ohne doppelten Boden.
Der große Boom um DeFi
Inzwischen stecken rund 60 Milliarden Dollar in diesen Protokollen. Der Hype lässt sich am besten mit jenem um ICOs im Jahr 2017 vergleichen, als Coins ohne Zweck endlos in den Himmel spekuliert wurden.
Im Mittelpunkt von DeFi steht das so genannte „yield farming“, bei dem es am Ende um die Erzielung einer Rendite geht – ohne dabei zu traden. Man stellt lediglich seine Coins zur Verfügung. Wofür auch immer. Die Verzinsung wird meist in Token der jeweiligen Plattform ausbezahlt, die dann auch stark im Wert schwanken. Klingt verrückt, gefährlich und verwirrend. Ganz genauso ist es.
Die irre neue Finanzwelt ist gefährlich
Aber DeFi hat längst die obskuren Ecken des Internets verlassen und Mark Cuban ist einer der Gründe dafür. Er liebt die kleine, virtuelle Gelddruckmaschine und erklärt das jedem, der es hören will. Es ist auch durchaus faszinierend, denn DeFi braucht keine Investoren, um Projekte zu starten. Man stellt sie einfach auf die grüne Wiese, bietet eine gewaltige Verzinsung und wartet bis die Menschen kommen und Liquidität mitbringen. Dann geht das Wachstum los.
Diese irre neue Finanzwelt kommt wie gesagt ohne Regulierung und Aufsicht aus. Sie läuft zum größten Teil sogar an Big Daddy Bitcoin vorbei, der eher sein eigenes Ding macht. Deswegen geht alles irre schnell – der Aufstieg und der Abstieg. Denn dieser Sektor wird natürlich auch von Betrügern besiedelt, wie die Website rekt.news genüsslich aufzählt. Seit gestern gehört auch Mark Cuban zu den Opfern eines „rug pulls“. Ihm wurde der Teppich unter den Füßen weggezogen.
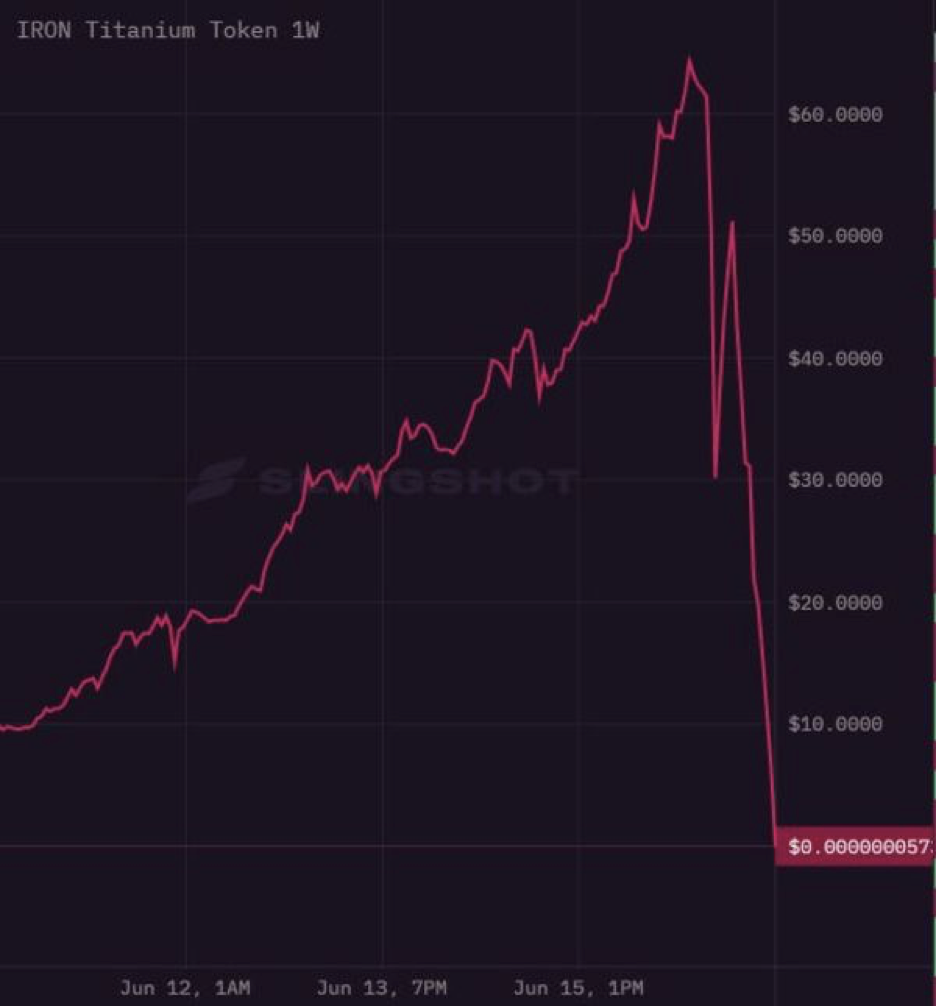
Eines seiner Projekte, Titan bzw. dessen Stablecoin IRON, ist binnen weniger Stunden von 60 Dollar auf exakt null gefallen. Blöderweise hat Cuban erst am Sonntag über seine Begeisterung für Titan (und andere DeFi-Plattformen) geschrieben. Das Wort „brilliant“ kommt vor. Cuban ist auch weiterhin der Meinung, dass Banken Angst vor DeFi haben sollten. Das mag sein, werden wir sehen.
„You live, you learn“, sagt DeFi-Opfer Cuban
Am Donnerstag, als das Geld dann weg war, hieß es von Cuban nur kurz: „You live, you learn“. Nun, das mag stimmen. DeFi steht wirklich ganz am Anfang. Und irgendwie ist es beruhigend, wenn auch Milliardäre wie Cuban auf einen Scam reinfallen. Aber das ist wenig Trost für die Menschen, die Cuban dank seiner Posts in den Abgrund gefolgt sind.
Deswegen hier nochmal die Warnung: Wer sich in den Kryptomarkt vorwagt, muss mit dem Schlimmsten rechnen. Wer auch bei DeFi einsteigt, sollte mit dem Schlimmsten rechnen – damit man nicht überrascht ist, wenn der Teppich gezogen wird.
Niko Jilch ist Finanzjournalist, Podcaster und Speaker. Website: www.nikolausjilch.com Twitter: @nikojilch
Disclaimer: Dieser Text sowie die Hinweise und Informationen stellen keine Steuerberatung, Anlageberatung oder Empfehlung zum Kauf oder Verkauf von Wertpapieren dar. Sie dienen lediglich der persönlichen Information. Es wird keine Empfehlung für eine bestimmte Anlagestrategie abgegeben. Die Inhalte von brutkasten.com richten sich ausschließlich an natürliche Personen.







