


Der neue Mobilfunkstandard 5G wird digitale Veränderungen in nahezu all unseren Bereichen der Wirtschaft und Gesellschaft anstoßen. Alle Anstrengungen des Ausbaus von Breitband und 5G haben allerdings nur dann einen größeren Nutzen, wenn auch das volle technische Potential der Gigabitnetze in Form von maßgeschneiderten Anwendungen genutzt werden.
Um die Entwicklung von Anwendungen zu beschleunigen, hat das Bundesministerium für Landwirtschaft, Regionen und Tourismus (BMLRT) gemeinsam mit der FFG daher mit der Gigabit Academy ein neues Serviceangebot geschaffen, das unter dem Dach „Gigabit Triple A: Awareness Applications Austria“ umgesetzt wird. Dazu zählt neben der „Gigabit Academy“ auch die parallel laufende Förderung „Breitband 2030 GigaApp“, die mit insgesamt 30 Millionen Euro dotiert ist.
Das neue Service- und Förderpaket richtet sich an Startups, KMU, Technologieunternehmen, Forschungseinrichtungen und öffentliche Organisationen aus dem Digitalbereich.
Das Ziel der Gigabit Academy
Die Vision der Gigabit Academy ist es, die richtigen Impulse zu setzen, um die Entwicklung von Gigabit und 5G Anwendungen in Österreich voranzutreiben. Dabei wird Wissen von Universitäten, Forschungseinrichtungen, Unternehmen und Organisationen gebündelt und stellt dieses den „Gigabit Academy“ Teilnehmer:innen in Form von Workshops, Vorträgen und Einzelcoachings zur Verfügung. Dies erfolgt in enger Zusammenarbeit mit zahlreichen Partnerorganisationen, die in Österreich zu den Front-Runnern im Bereich der 5G-Technologien zählen.
Diese Ziele stehen im Fokus
| 1. Entwicklungen von Gigabit und 5G Anwendungen anstoßen 2. Projekte und Kooperationen ermöglichen 3. Vernetzung und Aufbau der Gigabit Community 4. Knowhow Transfer 5. Awareness und Sichtbarkeit für Gigabit & 5G Themen |
Das bietet Gigabit Academy den Teilnehmer:innen
Die Gigabit Academy besteht aus einem exklusiv zusammengestellten Programm aus mehreren Rahmenevents und unterschiedlichen Workshops bei den Partnerorganisationen vor Ort – unter anderem auch mit individuellen Coachings. Hier ein Überblick über das Rahmenprogramm:
- Persönliches Kennenlernen der Partnerorganisationen (5G Playground, A1, AIT, Ars Electronica Center, Ericsson Austria, Euro CC, FH Hagenberg, Huawei, Hutchison Drei, Magenta Telekom, Salzburg Research, Siemens, Silicon Austrian Labs, TU Wien – Institute of Telecommunication, u.a.)
- Erfahrungen und Kontakte zu Knowhow Träger:innen aus Wirtschaft und Wissenschaft
- Internationale Perspektiven und Vernetzungsmöglichkeiten
- Unterstützung für Kooperationen und Partnerschaften
- Maßgeschneidertes und umfassendes Fachwissen
- Überblick zu Trends, Technologien und Branchen im Zusammenhang mit 5G & Gigabit Anwendungen wie z.B. Künstliche Intelligenz, IoT, Big Data, AR/VR, Simulationen, Robotik, um nur einige zu nennen
- Einblicke in viele aktuelle Use Cases und Unterstützung für mögliche eigene Use Cases wie z.B. aus den Bereichen, Industrie, Logistik, Mobilität, Sicherheit, Drohnen, Energie und viele andere
- Business Knowhow für zukünftige Projekte im Umfeld von Gigabit und 5G Applikationen
Wie erfolgt die Anmeldung zur Gigabit Academy?
Gesucht werden Personen und Unternehmen die entweder bereits an Gigabit und 5G Anwendungen arbeiten oder daran interessiert sind Projekte und Kooperationen im Gigabit-Anwendungsbereich zu starten.
Anhand von Motivationsfragen können sich interessierte Personen anmelden und werden nach dem First-Come-First-Served Prinzip ausgewählt. Danach erhält man die Möglichkeit das Gigabit Academy Programm hautnah bei den Partnerorganisationen zu erkunden und nimmt als Gigabit Academy Explorer teil.
Der Zeitplan der Gigabit Academy
Die Rahmenevents der Gigabit Academy dienen zum Wissensaufbau und zur Vernetzung.
| Das Kick-Off Event zur Gigabit Academy findet am 26. April 2022 von 9.00 bis 14.00 Uhr (MEZ) im Ars Electronica Center in Linz statt und wird auch auf die „Live Stage“ auf dieser Website gestreamt. Beim Kick-Off Event wird es International Gigabit Insights geben, die das Thema Gigabit und die internationalen Trends beleuchten und Showcases der Gigabit Academy Partnerorganisationen aufzeigen. Dabei hat man die Möglichkeit einen Vorgeschmack auf die verschiedenen Workshop-Module und das Knowhow zu aktuellen Gigabit-Entwicklungen der Partnerorganisationen zu erhalten |
Zudem wird es auch ein eigenes Austauschforum mit Südkorea während der ViennaUP’22 am 1. Juni geben. In keinem anderen Land der Welt ist 5G soweit ausgebaut und zählt so viele Endnutzer:innen wie Südkorea. Im Zentrum soll daher der Erfahrungsaustausch stehen.
Das Abschlussevent wird am 13. Juni 2022 in Klagenfurt stattfinden. Es ist als Abschluss der Workshopreihe angelegt und wird „Gigabit Academy Explorern“ und Partnerorganisationen offenstehen.
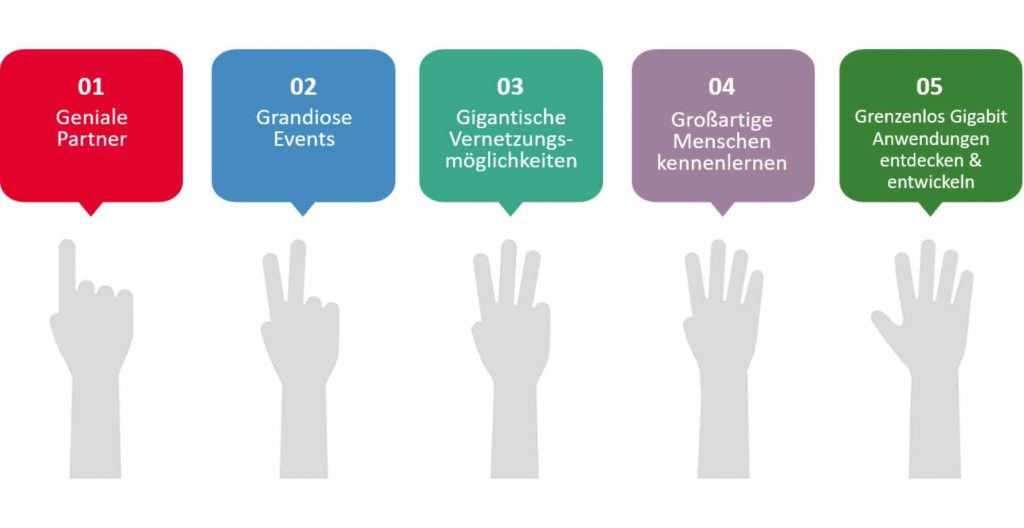
5 gute Gründe warum sich mitmachen lohnt
Keine aktuellen Informationen verpassen
Aktuelle Informationen werden laufend auf der Plattform der Gigabit Academy ergänzt. Um nichts zu verpassen, können sich Interessierte für einen eigenen Newsletter unter [email protected] anmelden. Zudem wird der brutkasten als Partner laufend über die Academy und wichtige Programmpunkte berichten.






