


Ein Smartphone besteht aus bis zu 60 verschiedenen Rohstoffen aus aller Welt. Ein Viertel davon sind Metalle und seltene Erden, die oftmals unter prekären Arbeitsbedingungen abgebaut werden. Studien zufolge verbraucht die Produktion von „einem Gramm Smartphone“ rund 80 Mal mehr Energie als die Produktion von „einem Gramm Auto“. Das Umweltproblem „Smartphone“ steht daher schon länger in der Kritik.
So funktioniert das Eco-Rating
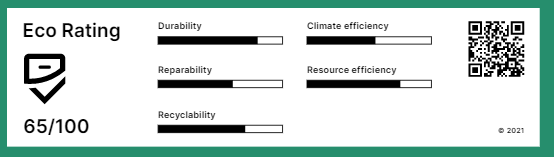
Eine neue Initiative führender europäischer Mobilfunkprovider möchte nun für mehr Transparenz sorgen und präsentierte Mitte der Woche das sogenannte Eco-Rating für Smartphones, das künftig die Konsumenten über die Nachhaltigkeit der Geräte informieren soll. Das Rating setzt sich aus insgesamt fünf Kategorien zusammen. Dazu zählen die Langlebigkeit, Reparaturfähigkeit, Recyclefähigkeit, Klimaverträglichkeit und Ressourcenschonung. Bei der Langlebigkeit soll beispielsweise die Robustheit des Gerätes bewertet werden. Außerdem soll die Akku-Nutzungsdauer und der Garantiezeitraum des Smartphones berücksichtigt werden. Wie die Provider erklären, werden allerdings nur Geräte bewertet, die neu auf den Markt kommen.
Wichtige Player machen nicht mit
Im Zuge des Ratings werden bis zu 100 Punkte vergeben werden, wobei sich die Gesamtbewertung für das angebotene Smartphone aus den Herstellerangaben berechnet. Derzeit kooperieren insgesamt zwölf Hersteller von Android-Smartphones, unter anderem Samsung, Huawei, Nokia, OnePlus, Lenovo (Motorola), Xiaomi und Alcatel. Die gesamte Liste der Provider und Hersteller findet sich auf der Website der Initiative.
Im Anschluss der Präsentation des Eco-Ratings gab es allerdings auch Kritik, dass sich wichtige Player am Markt, wie Apple, Sony oder Google, nicht an der Initiative beteiligen. Zudem steht der niederländische Hersteller Fairphone, der mit seinem besonders umweltfreundlichen Smartphone wirbt, nicht auf der Liste der Kooperationspartner. Vielfach war die Rede davon, dass ein derartiges Rating nur dann Sinn macht, wenn sich alle Hersteller geschlossen an der Initiative beteiligen.
Kritik am Punktesystem selbst
Neben der Tatsache, dass wichtige Player auf der Liste fehlen, wurde allerdings auch das Punkte-System selbst kritisiert, da beispielsweise der Software-Aspekt nicht berücksichtigt wurde. Peter Windischhofer, CEO von refurbed, kritisierte beispielsweise in einem Pressestatement. „Eine Punkte-Bewertung geht nicht weit genug. Die Hersteller müssen ihre Konzepte anpassen und sich ihrer Verantwortung stellen, Geräte einfacher reparierbar zu konstruieren und diese länger mit (Software-)Updates zu versorgen.“ Die fehlende Abwärtskompatibilität von Software-Updates führt in der Regel dazu, dass essentielle Sicherheitslücken entstehen und das Smartphone somit unbrauchbar wird. „Damit das neue Rating langfristig Effekte bringt, müssen elektronische Geräte auch leichter auf den technisch notwendigen Stand aufgerüstet werden können. Damit lässt sich der Produktlebenszyklus bis zum End-of-Life (EOF) deutlich verlängern“, so Windischhofer.
Factbox zum Thema Elektronik-Schrott
| Der durchschnittliche Europäer behält sein Smartphone nicht einmal zwei Jahre, obwohl es oftmals ohne Probleme fünf Jahre halten könnte. Ganze 80 Prozent der CO2-Emissionen, die während des gesamten Lebenszyklus eines Smartphones ausgestoßen werden, entstehen bei der Produktion. Und: Die weltweite Menge des Elektroschrotts erreichte im Jahr 2019 ein Rekordaufkommen von 53,6 Millionen Tonnen und wird den Vorhersagen der Vereinten Nationen zufolge bis zum Jahr 2030 rund 74 Millionen Tonnen erreichen. |


