


Die Kurstafel:
📈 Bitcoin steigt über 37.000 Dollar, Ethereum über 2.000 Dollar
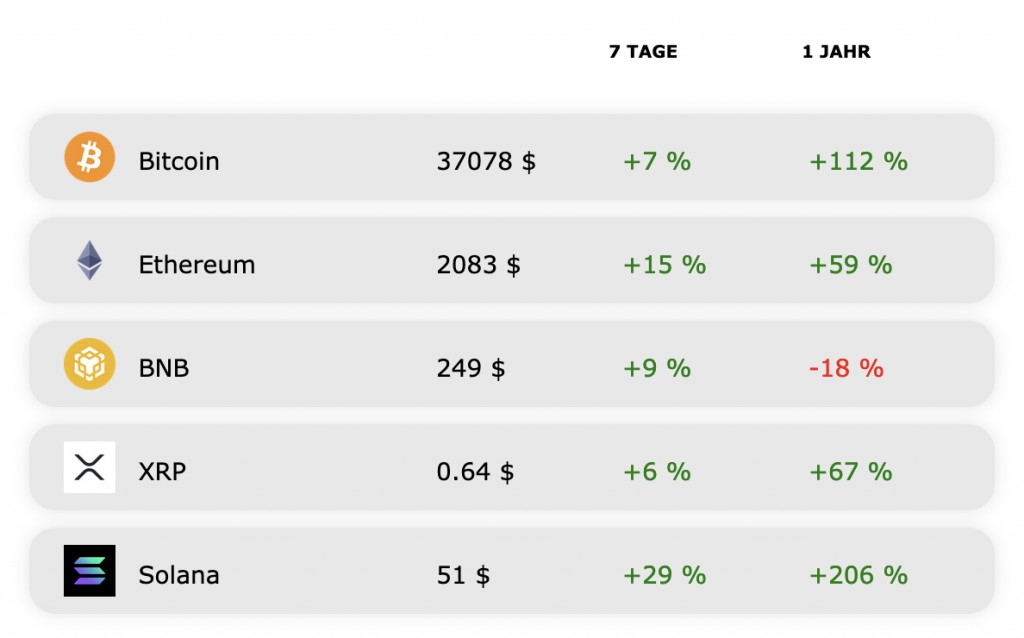
Wie immer starten wir mit dem Blick auf die Marktentwicklung. Die war diese Woche stark: Der Bitcoin-Kurs (BTC) ist weiter gestiegen und hat die Marke von 37.000 US-Dollar geknackt. Damit setzte er seine Aufwärtsbewegung der vergangenen Wochen fort und erreichte den höchsten Stand seit Mai.
Angetrieben wurde der Kurs dabei nach wie vor vom Hype um mögliche Zulassungen von Bitcoin-ETFs in den USA. Solche könnten kurz bevorstehen, hoffen viele am Kryptomarkt.
Eine noch stärkere Performance legte diese Woche allerdings Ethereum hin. Der Ether-Kurs (ETH) stieg seit vergangenem Freitag um 15 Prozent. Dabei überschritt er auch die Marke von 2.000 US-Dollar – erstmals seit Juli.
Der hauptsächliche Grund des starken Kursanstiegs ist auch einigermaßen einfach zu identifizieren – und er hängt mit BlackRock zusammen. Der weltgrößte Vermögensverwalter hatte den aktuellen Hype rund um einen möglichen Bitcoin-ETF im Juni ausgelöst, indem er einen entsprechenden Antrag bei der US-Börsenaufsicht eingereicht hatte. Die hat zwar noch nie einen ETF genehmigt, der direkt in Bitcoin investiert – allerdings auch noch fast nie einen Antrag von BlackRock abgelehnt.
🤔 Was man über BlackRocks Pläne zu einem Ethereum-ETF weiß
Was das mit Ethereum zu tun hat? Zunächst einmal nichts. Allerdings hat BlackRock nun diese Woche einen weiteren Antrag eingereicht. Und zwar auf einen iShares-Ethereum-Trust in Delaware. iShares ist eine bekannte ETF-Marke von BlackRock.
Ein solcher Trust ist kein ETF, aber: Kurz bevor BlackRock seinen Antrag auf einen Bitcoin-ETF bei der Börsenaufsicht eingereicht hat, hatte der Vermögensverwalter ebenfalls einen ähnlichen Antrag auf einen Bitcoin-Trust eingereicht.
Was schon reicht, um Spekulationen zu entfachen: Kommt nach dem Bitcoin-ETF von BlackRock auch ein Ethereum-ETF? BlackRock selbst wollte dies auf Anfrage des US-Branchenmagazins Decrypt nicht kommentieren.
Doch auch wenn sich BlackRock selbst noch nicht geäußert hat: Es gibt ein anderes starkes Indiz. Die US-Börse Nasdaq hat einen Antrag bei der US-Börsenaufsicht gestellt, den besagten iShares Ethereum Trust von BlackRock zu listen.
Grundsätzlich ist die Situation bei einem solchen Ethereum-ETF ganz ähnlich wie jene bei den Bitcoin-ETFs: Bisher sind in den USA nur ETFs zugelassen worden, die in Ethereum-Futures investieren. Also in Finanzprodukte, die den Ether-Kurs nachbilden. Nicht in Ether selbst. Ein “richtiger” Ethereum-ETF würde zusätzliches Geld in den Markt bringen, die Nachfrage nach Ether-Token erhöhen und somit auch den Kurs antreiben – so zumindest die Hoffnung am Kryptomarkt.
Ob sich diese bestätigen wird, ist zum jetzigen Zeitpunkt völlig offen. Unterscheiden sollte man zudem zwischen kurz- und langfristigen Auswirkungen: Dass ein Ethereum-ETF die Nachfrage nach Ether langfristig erhöhen wird, ist durchaus plausibel: Er würde es einfacher machen, in Ether zu investieren – und könnte Ether-Investments neuen Gruppen zugänglich machen.
Die kurzfristige Auswirkung auf den Kurs ist davon aber mehr oder weniger unabhängig – und eher von Spekulation getrieben. Wenn sich bestätigt, dass BlackRock den Antrag einreichen wird (wonach es aktuell aussieht), heißt das nicht notwendigerweise, dass der Ether-Kurs weiter steigen muss.
Nicht einmal eine Genehmigung des Antrags würde notwendigerweise einen unmittelbaren Kursanstieg bedeuten. Häufig werden solche Ereignisse von der Kursentwicklung bereits vorweggenommen und sind zum Zeitpunkt, an dem sie sich bestätigen, bereits vollständig eingepreist. Nicht umsonst lautet eine alte Börsenweisheit: “Buy the rumour, sell the news”




