


Wenn OpenAI neue Dinge ankündigt, hört die KI-Szene hin. Klar, nicht jede Ankündigung des US-Unternehmens in den vergangenen zwei Jahren hatte dieselbe Tragweite wie jene vom 30. November 2022, als OpenAI den Start eines Chatbots namens ChatGPT verlautbaren ließ. Aber potenziell könnte jede Mitteilung des Unternehmens rund um CEO Sam Altman bahnbrechend sein. Kein Wunder also, dass es für Aufsehen sorgte, als OpenAI Anfang Dezember verlautbarte, zwölf Tage hintereinander neue Dinge vorzustellen.
Schon in der Ankündigung hatte Altman darauf hingewiesen, dass es neben größeren auch kleinere Neuigkeiten sein würden, die OpenAI liefern würde. So kam es dann auch: Zugang zu ChatGPT über WhatsApp oder die Integration in Apple Intelligence waren eher in die zweite Kategorie einzuordnen. Daneben veröffentlichte OpenAI aber auch das neue Modell o1 für ChatGPT – oder Sora, ein Tool zur Videoerstellung.
Den größten Widerhall in der KI-Szene fand allerdings die Ankündigung am letzten der zwölf Tage. Am vergangenen Freitagabend stellte OpenAI sein neues Modell o3 vor. Wichtig dabei: Das Modell ist noch nicht öffentlich zugänglich. OpenAI stellte zunächst einmal nur vor, wie das Modell in unterschiedlichen KI-Benchmarks abschnitt. Aber diese Ergebnisse hatten es in sich.
o3 zeigt starke Performance bei AGI-Benchmark
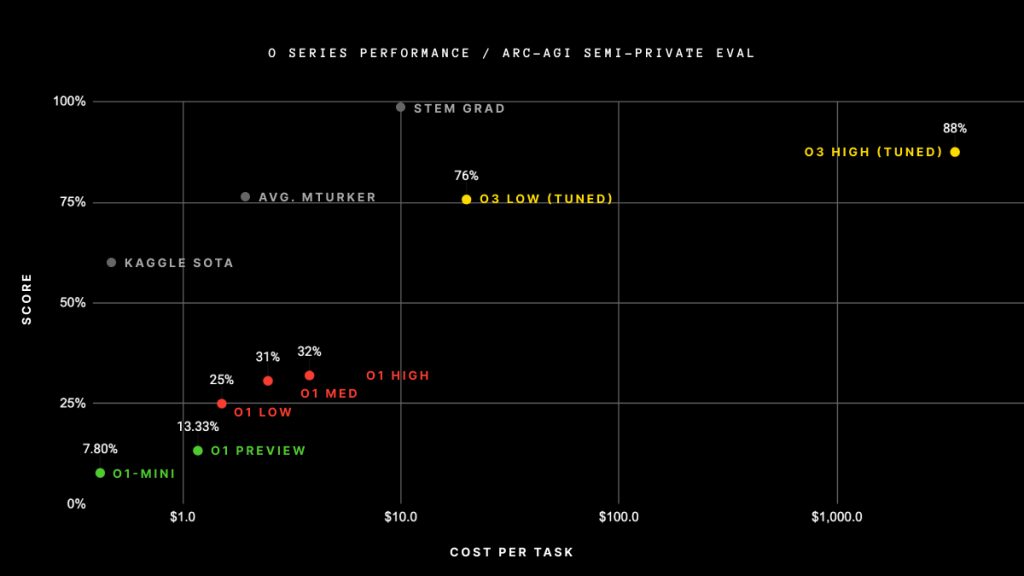
Vielbeachtet wurde dabei vor allem die Benchmark namens ARC-AGI (Abstraction and Reasoning Corpus for Artificial General Intelligence), bei der zwei Varianten des o3-Modells deutlich bessere Ergebnisse erzielten als die bisher führenden o1-Modelle. Das Ziel von ARC-AGI ist es zu messen, wie sich eine KI im Umgang mit ihr unbekannten Aufgaben schlägt.
Es gibt unterschiedliche Definitionen von AGI. Die meisten davon verstehen AGI aber als ein System, das sämtliche intellektuellen Aufgaben mindestens so gut oder besser als ein Mensch erledigen kann.
Die ARC-AGI-Benchmark wurde von François Chollet konzipiert. Er definiert AGI als ein System, das „in der Lage ist, effizient neue Fähigkeiten zu erwerben und neuartige Probleme zu lösen, für die es trainiert wurde.“
Eine AGI ist also nicht für eine bestimmte Aufgabe trainiert, sondern kann jegliche Aufgaben übernehmen. Es ist weitgehender Konsens in der KI-Szene, dass solche Systeme noch nicht existieren. OpenAI wurde aber beispielsweise explizit mit dem Ziel gegründet, AGI zu erreichen.
Chollet gehört zu den bekanntesten Namen der internationalen KI-Szene. Er hat die bekannte KI-Library Keras entwickelt und seit einigen Jahren für Google tätig. Dem von ChatGPT ausgelösten Hype rund um generative KI steht Chollet seit Anfang an eher kritisch gegenüber, wie beispielsweise auch dieser brutkasten-Bericht wenige Wochen nach Erscheinen von ChatGPT thematisierte.
o3: „Wir befinden uns auf neuem Terrain“
Umso interessanter ist es, was Chollet nun zu den Ergebnissen des o3-Modells bzw. seiner Varianten zu sagen hat. In einem Blogeintrag attestiert er OpenAI, mit dem Modell einen „bedeutenden Sprung nach vorne“ erreicht zu haben.
Die Performance des Modells stelle „einen echten Durchbruch“ in der Anpassungsfähigkeit und Verallgemeinerung“ von KI-Modellen dar“, wenn es darum gehe, wie sich KI-Modelle an neue Aufgaben anpassen könnten. o3 stelle nicht bloß einen „schrittweisen Fortschritt“ dar. Vielmehr befinde man sich auf „neuem Terrain“, das „ernsthafte wissenschaftliche Aufmerksamkeit“ erfordere.
Aber es ist schon Artificial General Intelligence (AGI)? Hier schränkt Chollet ein: „o3 scheitert immer noch an einigen sehr einfachen Aufgaben, was auf grundlegende Unterschiede zur menschlichen Intelligenz hinweist“. Dennoch befeuerten die Ergebnisse die Diskussion rund um AGI – und manche Stimmen sahen, anderes als Chollet, mit o3 AGI sogar bereits erreicht.
Selbst wenn dem so wäre, wäre es zum jetzigen Zeitpunkt schwer nachzuprüfen: Denn das Modell ist noch nicht veröffentlicht. Forscher:innen im Bereich der KI-Sicherheit können sich für Zugang vormerken lassen. Wann und zu welchen Konditionen das Modell für Endnutzer:innen zugänglich sein wird, ist aktuell noch unklar. Klar ist allerdings schon jetzt, dass die beeindruckenden Ergebnisse bei der ARC-AGI-Benchmark enorme Rechenressourcen erforderten – und dementsprechend teuer waren.
Reasoning-Modelle
Das o3-Modell ist eine verbesserte Version des o1-Modells, welches OpenAI am 4. Dezember veröffentliche und das zuvor bereits in Preview- und Mini-Varianten für ChatGPT-User:innen zugänglich gewesen war. Dieses Modell unterscheidet sich zu dem im Mai 2024 veröffentlichten GPT4o-Modell insofern, als es auf einen „Reasoning“-Ansatz setzt.
OpenAI bezeichnet GPT4o weiterhin als das „vielseitige, hochintelligente Flagship-Modell“, das für die „meisten Aufgaben“ die richtige Wahl sei. Die o1-Modelle wiederum referenziert das Unternehmen als „Reasoning-Modelle, die sich bei komplexen, mehrstufigen Aufgaben auszeichnen“.
Enduser:innen von ChatGPT merken dies in der Nutzung vor allem insofern, als sich die o1-Modelle länger Zeit nehmen, Ergebnisse zu produzieren. Diese Modelle „verbringen mehr Zeit mit Nachdenken, bevor sie reagieren“, wie es OpenAI formuliert. In einigen (aber nicht notwendigerweise in allen) Bereichen liefern sie dann deutlich bessere Ergebnisse als die bisherigen Modelle.
Tipp der Redaktion: Die neue brutkasten-Serie „No Hype KI“





